Copy Fail Changes the Security Conversation
")
Copy Fail Changes the Security Conversation
Why Infrastructure Accountability Matters More Than Ever
On April 29, 2026, security researchers disclosed one of the most alarming Linux privilege escalation vulnerabilities in years: “Copy Fail” (CVE-2026-31431).
At first glance, it may have looked like just another Linux kernel vulnerability announcement. But Copy Fail represents something far more serious. The exploit was reliable, quiet, easy to execute, and effective across nearly every major Linux distribution released since 2017. Even more concerning, researchers indicated that AI-assisted analysis helped accelerate discovery and exploitation research, highlighting a rapidly changing cybersecurity landscape where dangerous vulnerabilities can move from discovery to weaponization faster than most organizations can operationally respond.
For businesses running SaaS platforms, Kubernetes clusters, CI/CD pipelines, virtualized infrastructure, or cloud-hosted Linux workloads, Copy Fail is a reminder that infrastructure can no longer be treated as a commodity. Modern environments require intentional engineering, continuous oversight, and operational accountability.
This is where Application-Aware Infrastructure (AAI) changes the conversation.
What Is Copy Fail?
Copy Fail is a critical Linux kernel local privilege escalation vulnerability affecting the kernel’s cryptographic subsystem, specifically the algif_aead and authencesn components. The flaw traces back to a kernel optimization introduced in 2017. The optimization unintentionally enabled writable page cache manipulation within the Linux kernel. The result? An unprivileged user could gain root-level access using a relatively small and simple Python script.
What made the vulnerability especially alarming was not just the ability to escalate privileges, but how quietly it could happen. Attackers could modify privileged binaries in memory without altering the actual file stored on disk. That distinction is important because many traditional security tools still rely heavily on file-based monitoring, hash validation, and integrity checking. If the file itself never changes, many organizations may have little visibility into the attack taking place.
Researchers also demonstrated the potential for container escapes in shared Kubernetes environments, compromise of CI/CD systems, and attacks against cloud-hosted Linux workloads. The exploit proved highly portable across environments, making it operationally dangerous for organizations running modern Linux infrastructure at scale.
Copy Fail manipulated behavior in memory, making detection significantly harder for organizations relying solely on traditional endpoint security approaches.
Why Copy Fail Is Different
Many severe vulnerabilities require a complicated series of steps to successfully exploit. Attackers often need precise timing, highly customized environments, or multiple chained weaknesses to gain meaningful access. Copy Fail dramatically lowered that barrier.
Researchers described it as extremely reliable, consistent across distributions, easy to weaponize, and highly stealthy. That level of consistency fundamentally changes risk exposure because it allows attackers to move faster and more confidently. A vulnerability that works consistently across environments becomes much easier to operationalize in real-world attacks.
This is part of a larger shift occurring across cybersecurity. Threat actors no longer need the same level of sophistication that was once required to exploit advanced infrastructure weaknesses. As offensive research becomes more automated and AI-assisted tooling becomes more accessible, the timeline between vulnerability discovery and active exploitation continues to shrink.
AI Is Accelerating the Cybersecurity Arms Race
While the technical details of Copy Fail are important, the larger story may be even more significant. Researchers reportedly used AI-assisted analysis to help surface the vulnerability rapidly. AI is now accelerating vulnerability discovery, exploit development, reverse engineering, malware modification, and attack automation at a pace the industry has never experienced before.
Historically, discovering deep kernel vulnerabilities required highly specialized expertise and significant research time. Today, AI-assisted workflows can dramatically compress portions of that process. Attackers and researchers alike can analyze code faster, identify weak patterns more efficiently, and automate portions of offensive security research that previously demanded extensive manual effort.
For organizations, this means the operational window for response is shrinking. Vulnerabilities may move from disclosure to active exploitation in hours instead of weeks. Security can no longer rely on slow patch cycles, fragmented ownership, or reactive operational models.
The Real Problem Is Operational Security
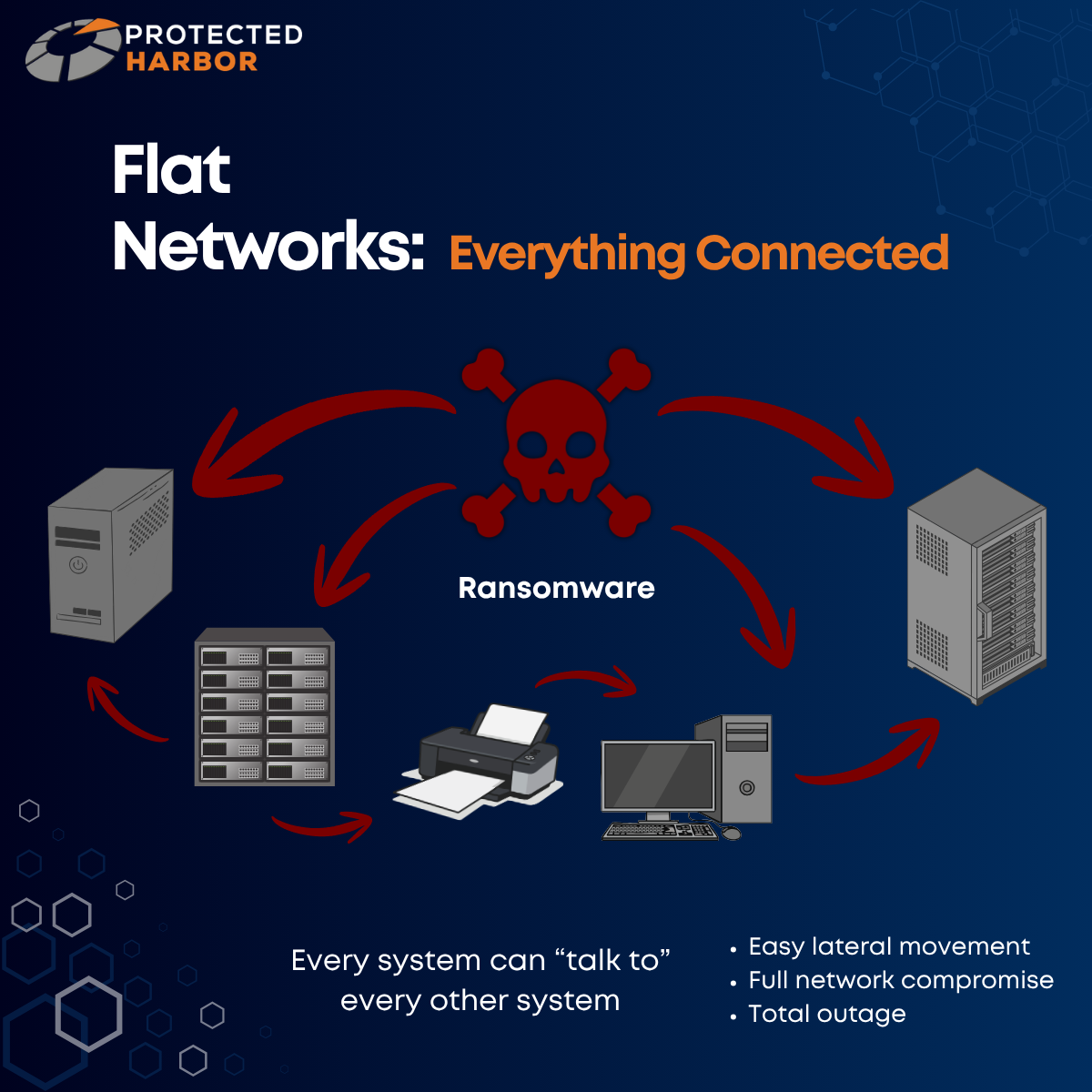
Most organizations still approach cybersecurity primarily through tooling. When new threats emerge, the instinct is often to purchase another endpoint product, add another SIEM, deploy another EDR agent, or implement another layer of monitoring software. However, modern threats increasingly exploit operational weaknesses rather than missing tools:
- Misconfigured infrastructure
- Shared environments
- Weak segmentation
- Poor visibility
- Excessive permissions
In many organizations, infrastructure responsibility is fragmented across multiple vendors, internal teams, and cloud providers. When a major vulnerability emerges, nobody has complete operational accountability.
That creates dangerous delays.
Teams suddenly begin asking who owns remediation, who validates exposure, who coordinates updates, and who is responsible for verifying the environment is secure afterward. In fast-moving security incidents, that confusion becomes a vulnerability in itself.
Infrastructure accountability is rapidly becoming one of the most important components of modern cybersecurity.
Why Infrastructure Accountability Matters
Security tools are important, but accountability is what determines how effectively organizations respond under pressure. Modern infrastructure environments are too complex for passive management models. Organizations need operational ownership from teams that deeply understand the applications, workloads, dependencies, and infrastructure layers involved.
That ownership includes continuous monitoring, lifecycle management, proactive vulnerability response, segmentation oversight, and operational governance. Without it, even well-funded environments can struggle during critical incidents.
As threats accelerate, operational maturity becomes just as important as technical capability.
How Protected Harbor Helps Mitigate Threats Like Copy Fail
Protected Harbor’s Application-Aware Infrastructure model was designed specifically to address the operational gaps that modern threats increasingly exploit. Rather than treating infrastructure as generic compute resources, Protected Harbor engineers environments around the actual behavior and requirements of the applications they support. That deeper operational understanding becomes critical when responding to vulnerabilities like Copy Fail.
1. Rapid Patch Management & Operational Ownership
When major vulnerabilities emerge, response time matters. Many organizations struggle because internal teams are already stretched thin or because infrastructure ownership is fragmented across providers and departments. Protected Harbor helps streamline response through active infrastructure monitoring, managed operating systems, coordinated patch management, kernel oversight, and lifecycle governance.
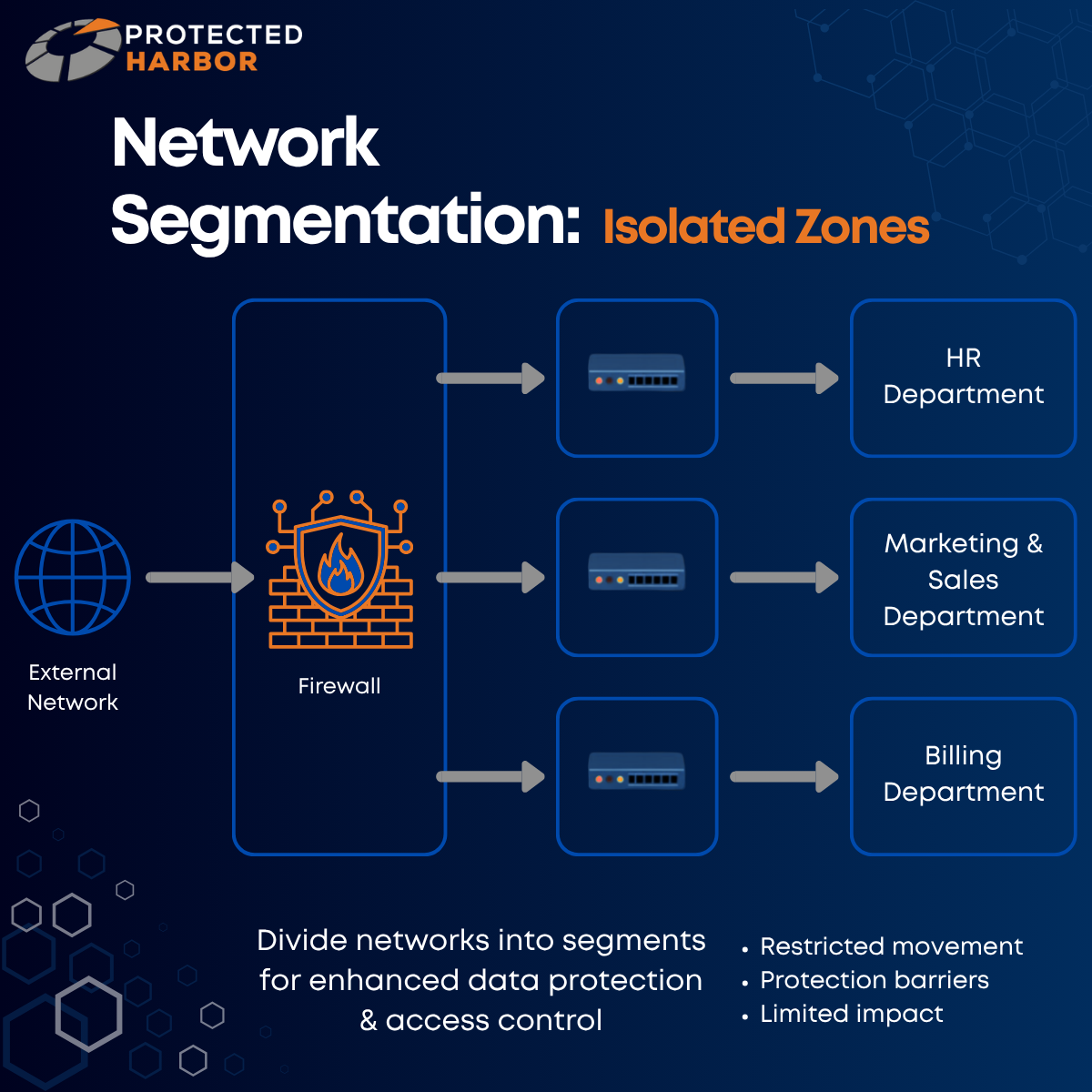
2. Zero Trust Architecture Reduces Blast Radius
Copy Fail is dangerous because it allows privilege escalation immediately after initial access is achieved. Protected Harbor’s Zero Trust approach helps reduce risk through:
- Segmented environments
- Identity-based access controls
- Least privilege enforcement
- Network isolation
- Dedicated tenant architectures
- Continuous authentication policies
Even if an attacker gains foothold access, properly engineered segmentation can significantly limit lateral movement and contain exposure.
3. Application-Aware Infrastructure Detects Abnormal Behavior Faster
Protected Harbor emphasizes visibility beyond traditional infrastructure metrics. Modern attacks often reveal themselves operationally before they trigger conventional security alerts. By understanding expected workloads, user behavior, service dependencies, authentication patterns, and application baselines, Application-Aware Infrastructure can help organizations identify abnormal activity earlier and respond faster.
4. Dedicated Environments Reduce Shared Infrastructure Exposure
Dedicated infrastructure further reduces shared-environment risk. In heavily shared environments, vulnerabilities affecting kernels or containerization layers can create broader exposure concerns. Protected Harbor’s private cloud and dedicated infrastructure offerings help organizations reduce these risks through isolated workloads, dedicated Active Directory environments, controlled infrastructure layers, and custom security policies tailored to the application itself.
5. Continuous Security Oversight
Protected Harbor’s managed security and vCISO services help organizations maintain:
- Ongoing vulnerability management
- External scanning
- Security benchmarking
- Risk assessments
- Patch governance
- Incident preparedness
- Compliance alignment
Security cannot be a one-time initiative; it requires continuous operational discipline.
AI Is Accelerating Both Innovation & Risk
Copy Fail is more than a Linux vulnerability story. It is a warning about where cybersecurity is headed. AI is accelerating innovation, infrastructure scale, vulnerability discovery, and attacker capability all at once. Organizations can no longer rely solely on reactive security models or generic infrastructure strategies.
The environments that remain resilient moving forward will be the ones built around operational accountability, continuous monitoring, application awareness, and security-first engineering principles.
At Protected Harbor, we believe infrastructure should do more than simply exist. It should be intentionally engineered around the applications it supports, continuously monitored for abnormal behavior, strategically secured against evolving threats, and operationally owned by a single partner accountable for outcomes.
Because when the next critical vulnerability emerges — and it will — the organizations that respond fastest and operate most intelligently will be the ones that stay secure and operational.
Contact our team for a complimentary Infrastructure Risk Assessment where we will evaluate your environment and identify:
- Areas of vulnerability
- Cyberattack blast radius
- Performance bottlenecks tied to infrastructure design
No obligation — just clarity on where you stand.

")


")